- CHAPTER 1. 경제문제와 경제체제
- 역사적 대분기와 자본주의의 등장
학습 목표
인류 역사상 소득이 급격히 증가하기 시작한 ‘대분기(Great Divergence)’ 현상을 데이터로 확인한다.
자본주의를 구성하는 세 가지 핵심 제도(사유재산, 시장, 기업)를 이해한다.
왜 자본주의가 기술 발전과 전문화를 통해 경제 성장을 이끌었는지 논리적으로 설명한다.
1.1 인류 역사의 하키 스틱 (The Hockey Stick of History)
경제학을 배우기 전, 우리는 먼저 아주 근본적인 질문을 던져야 합니다. “우리는 과거의 인류보다 얼마나, 그리고 왜 더 풍요로운가?”
데이터로 보는 역사: 정체와 급성장
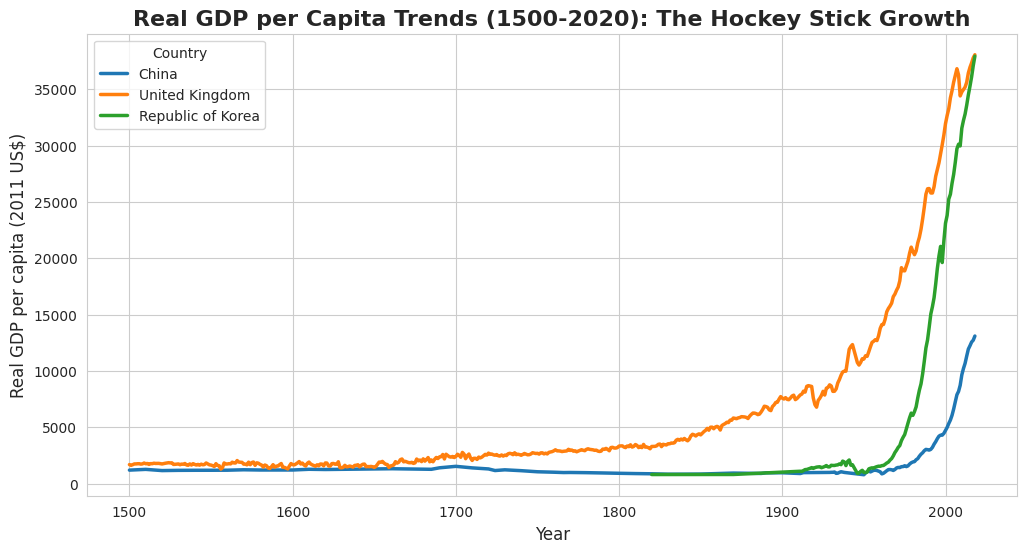
이 질문에 답하기 위해 우리는 역사적 데이터를 살펴볼 필요가 있습니다. 영국의 경제사학자 앵거스 매디슨(Angus Maddison)이 주도한 **매디슨 프로젝트(Maddison Project Database)**는 서기 1000년부터 현재까지 전 세계의 1인당 실질 GDP 추이를 추적했습니다.
이 데이터를 그래프로 그려보면 매우 놀라운 패턴이 나타납니다.
긴 정체기 (1000년 ~ 1700년대): 그래프는 수백 년 동안 바닥에 붙어 거의 평평한 모습을 보입니다. 이 시기 인류의 생활 수준은 오늘날과 비교하면 거의 변화가 없었으며, 대부분의 사람들은 생존 수준(subsistence level)의 소득에 머물러 있었습니다.
변곡점 (18세기 후반): 18세기 영국을 시작으로 그래프가 갑자기 위로 솟구치기 시작합니다.
급성장기 (19세기 ~ 현재): 이후 소득은 수직에 가깝게 상승합니다.
이 그래프의 모양이 마치 필드하키의 스틱(채)과 닮았다고 하여 이를 **‘역사의 하키 스틱(The Hockey Stick of History)’**이라고 부릅니다. 경제학에서는 이 결정적인 전환점을 **대분기(Great Divergence)**라고 합니다.
한국의 하키 스틱: 압축 성장
이러한 패턴은 서구 선진국에서만 나타난 것이 아닙니다. 한국은행과 통계청의 데이터를 보면, 한국은 20세기 중반까지도 1인당 소득이 매우 낮은 수준에 머물러 있었습니다. 그러나 1960년대 이후 불과 반세기 만에 서구 국가들이 200년에 걸쳐 이룩한 성장을 달성했습니다. 한국의 하키 스틱은 손잡이 부분이 훨씬 더 가파른, 전형적인 압축 성장의 모델을 보여줍니다.
[생각해보기] 왜 인류는 수천 년간 가난에서 벗어나지 못하다가, 하필 18세기 이후, 특정 지역에서부터 갑자기 부유해지기 시작했을까요? 무엇이 이 변화를 만들었을까요?
1.2 성장의 엔진: 기술 진보와 인구론
기술의 지속적 혁신
하키 스틱의 굴절 부분(변곡점)은 **산업혁명(Industrial Revolution)**의 시기와 일치합니다. 증기기관, 방적기, 전기의 발명은 인간의 근력에 의존하던 생산 방식을 기계의 힘으로 전환시켰습니다.
과거: 기술 발전이 있어도 인구가 늘어나면 다시 1인당 소득이 줄어드는 '맬서스 함정(Malthusian Trap)'에 갇혔습니다. (토머스 맬서스의 인구론)
산업혁명 이후: 기술 진보의 속도가 인구 증가 속도를 압도하기 시작했습니다. 이것이 지속적인 소득 증가를 가능하게 한 첫 번째 요인입니다.
하지만 기술만으로는 충분한 설명이 되지 않습니다. 과학적 지식이나 기술이 있어도 그것이 경제적 생산으로 연결되지 않는 경우도 많았기 때문입니다. 기술이라는 엔진을 돌릴 '차체’가 필요했습니다.
1.3 자본주의 혁명 (The Capitalist Revolution)
경제학자들은 대분기의 근본 원인을 **제도(Institution)**의 변화에서 찾습니다. 18세기 이후 확산된 새로운 경제 체제, 바로 **자본주의(Capitalism)**입니다.
자본주의는 단순히 '돈을 중시하는 태도’가 아닙니다. 경제학적으로 자본주의는 다음 세 가지 핵심 제도가 결합된 경제 체제를 의미합니다.
(1) 사유재산권 (Private Property)
정의: 개인이 토지, 건물, 기계, 지적 재산 등 가치 있는 자산을 소유하고, 사용할 수 있는 권리입니다.
기능: 내 것이라는 보장이 있어야 사람들은 투자하고, 관리하고, 혁신합니다. 농부가 수확물을 영주에게 빼앗긴다면 굳이 열심히 농사를 지을 유인이 없을 것입니다.
(2) 시장 (Markets)
정의: 재화나 서비스가 교환되는 물리적 또는 가상의 공간입니다. 시장에서의 교환은 강제나 약탈이 아니라, 상호 이득을 위한 자발적 교환입니다.
기능: 가격 신호(Signal)를 통해 희소한 자원을 가장 필요한 곳으로 배분합니다. 또한 경쟁을 통해 더 싸고 좋은 제품을 만들도록 유도합니다.
(3) 기업 (Firms)
정의: 자본을 소유한 사람이 직원을 고용하여 재화나 서비스를 생산하고 시장에 판매하여 이윤을 추구하는 조직입니다.
차이점: 과거의 가족 경영이나 국영 농장과 달리, 기업은 시장 수요에 따라 빠르게 규모를 확장하거나 축소할 수 있으며, 이윤 극대화라는 명확한 목표를 가집니다.
논리의 완성: 제도는 어떻게 성장을 이끄는가?
이 세 가지 제도는 다음과 같은 메커니즘으로 성장을 견인했습니다.
경쟁의 압력: 시장에서 살아남기 위해 기업은 끊임없이 **혁신(기술 도입)**해야 합니다. (비용 절감의 유인)
전문화와 분업: 시장이 확대되면서 개인과 국가는 자신이 가장 잘하는 것에 집중하는 **비교우위(Comparative Advantage)**를 활용하게 됩니다. 애덤 스미스는 『국부론』에서 핀 공장의 예시를 통해 분업이 얼마나 생산성을 비약적으로 높이는지 보여주었습니다.
확대 재생산: 사유재산권이 보장되므로, 기업가는 번 돈을 다시 기술과 설비에 재투자합니다.
1.4 경제문제: 희소성과 선택
자본주의가 비약적인 생산력 증대를 가져왔지만, 경제학의 본질적인 고민이 사라진 것은 아닙니다. 오히려 더 복잡해졌습니다.
희소성 (Scarcity): 인간의 욕망은 무한하지만, 자원(시간, 돈, 천연자원)은 한정되어 있습니다. 이는 자본주의 사회에서도 변함없는 진리입니다.
선택의 문제: 희소성은 필연적으로 선택을 강요합니다. 하나를 선택하면 다른 하나를 포기해야 합니다. 이때 포기한 것의 가치를 **기회비용(Opportunity Cost)**이라고 합니다.
우리가 앞서 살펴본 ‘하키 스틱’ 성장조차도 공짜는 아니었습니다. 급격한 성장은 **불평등(Inequality)**의 심화와 환경 오염이라는 새로운 비용을 발생시켰습니다.
현대 경제학은 단순히 "어떻게 성장할 것인가"를 넘어, 희소한 자원을 어떻게 효율적이고(Efficiency) 공평하게(Equity) 배분할 것인가를 연구합니다. 다음 장에서는 이 복잡한 문제를 다루기 위해 경제학자들이 사용하는 도구인 '모형(Model)'에 대해 알아보겠습니다.
import pandas as pd
# URL for the Maddison Project Database 2020
url = "https://www.rug.nl/ggdc/historicaldevelopment/maddison/data/mpd2020.xlsx"
# Load the dataset from the 'Full data' sheet
df_mpd = pd.read_excel(url, sheet_name='Full data')
# Display the first few rows
df_mpd.head()# List of target countries
target_countries = ['South Korea', 'United Kingdom', 'China']
# Filter for target countries and years 1500-2020
df_filtered = df_mpd[
(df_mpd['country'].isin(target_countries)) &
(df_mpd['year'] >= 1500) &
(df_mpd['year'] <= 2020)
].copy()
# Drop rows with missing gdppc values
df_filtered = df_filtered.dropna(subset=['gdppc'])
# Reset index
df_filtered = df_filtered.reset_index(drop=True)
# Display the first few rows and verify selected countries
print("Unique countries in filtered data:", df_filtered['country'].unique())
df_filtered.head()Unique countries in filtered data: ['China' 'United Kingdom']
print([c for c in df_mpd['country'].unique() if 'Korea' in str(c)])['Republic of Korea', 'D.P.R. of Korea']
# Update target countries with the correct name for South Korea
target_countries = ['Republic of Korea', 'United Kingdom', 'China']
# Filter for target countries and years 1500-2020
df_filtered = df_mpd[
(df_mpd['country'].isin(target_countries)) &
(df_mpd['year'] >= 1500) &
(df_mpd['year'] <= 2020)
].copy()
# Drop rows with missing gdppc values
df_filtered = df_filtered.dropna(subset=['gdppc'])
# Reset index
df_filtered = df_filtered.reset_index(drop=True)
# Verify the unique countries in the filtered dataset
print("Unique countries in filtered data:", df_filtered['country'].unique())
df_filtered.head()Unique countries in filtered data: ['China' 'United Kingdom' 'Republic of Korea']
import matplotlib.pyplot as plt
import seaborn as sns
# Set the seaborn style
sns.set_style("whitegrid")
# Initialize the figure
plt.figure(figsize=(12, 6))
# Create the line plot
sns.lineplot(data=df_filtered, x='year', y='gdppc', hue='country', linewidth=2.5)
# Set chart title and labels
plt.title("Real GDP per Capita Trends (1500-2020): The Hockey Stick Growth", fontsize=16, fontweight='bold')
plt.xlabel("Year", fontsize=12)
plt.ylabel("Real GDP per capita (2011 US$)", fontsize=12)
# Ensure legend is visible and display the plot
plt.legend(title='Country')
plt.show()